
Every few months we highlight a subset of the new plasmids in the repository through our hot plasmids articles. These articles provide brief summaries of recent plasmid deposits and we hope they'll make it easier for you to find and use the plasmids you need. If you'd ever like to write about a recent plasmid deposit please sign up here.
Listen to the hot plasmids episode!New, highly efficient RNAi construct for C. elegans gene knockdown
Article contributed by Alyssa Cecchetelli![]() Listen to the C. elegans RNAi podcast segment
Listen to the C. elegans RNAi podcast segment
RNA interference (RNAi) is extensively used in C. elegans research to study gene function. RNAi is commonly achieved by feeding E. coli expressing dsRNA to C. elegans. These dsRNAs target specific mRNA transcripts for degradation. Despite how easy these experiments are to physically set up in the lab, RNAi is often completely ineffective or results in low penetrant phenotypes that are hard to study. To overcome this, most scientists use mutant animals that are genetically altered to overexpress endogenous RNAi pathways. These mutations however can interfere with other genetic pathways making it difficult to link a phenotype to the gene being targeted via RNAi.
Recently the Vellai lab has created an improved RNAi vector that leads to significantly stronger phenotypes than standard RNAi protocols without the need for mutant genetic backgrounds. The standard RNAi vector, L4440, places a target gene between two inverted T7 promoters. Transcription from each promoter progresses past the specific gene producing long unspecific RNA fragments that are incorporated into the dsRNA necessary for RNAi. The Vellai lab’s new plasmid, T444T, contains T7 terminators adjacent to the T7 promoters to prevent the incorporation of non-specific nucleotides into the dsRNA leading to increased RNAi efficiency.
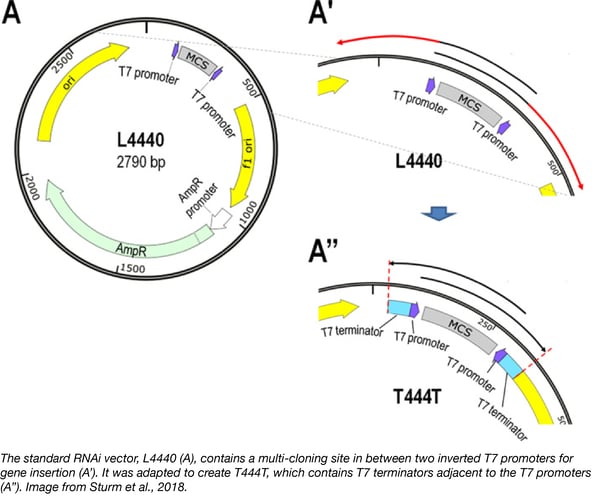
Strum A, et al. Nucleic Acids Research. 2018 PubMed PMID: 29924347
Faster proximity labeling with TurboID and miniTurbo
Article contributed by Eric Perkins![]() Listen to the TurboID and miniTurbo podcast segment
Listen to the TurboID and miniTurbo podcast segment
A fundamental approach to studying membranes, organelles, and other subcellular compartments is via proteomics--the study of the distribution and interactions of proteins within these structures. Enzyme-catalyzed proximity labeling (PL) uses a promiscuous labeling enzyme and a small-molecule substrate to map the spatiotemporal distribution and interaction networks of specific proteins in living cells. Until recently, the enzymes most frequently used for PL were APEX2 and BioID. APEX2 is fast, tagging proximal proteins within minutes, but requires H2O2, which can be toxic in living cells. BioID was derived from biotin ligase and uses far less toxic biotin for labeling, but the process is much slower and can take as long as several days.
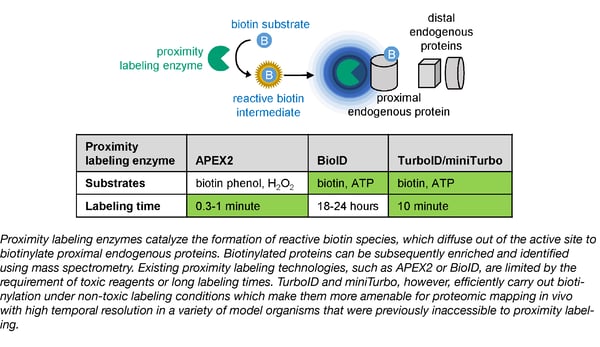 In 2015, the laboratory of long-time Addgene depositor Alice Ting used yeast display-based directed evolution to create APEX2. They have now applied the same directed evolution technique to the biotin ligase from which BioID was derived, creating a pair of enzymes that overcome both the speed and toxicity limitations of APEX2 and BioID. In the Ting Lab’s recent Nature Biotechnology paper, they describe TurboID and miniTurbo, which utilize non-toxic biotin, but label nearly as quickly as APEX2. What’s more, since the enzymes were ”evolved” in yeast at 30℃, the enzymes function across a much broader temperature range than BioID, which only functions optimally at 37℃. The increased efficiency of TurboID and miniTurbo makes PL a viable method for proteomics in model organisms in which it was previously not an option, including Drosophila and C. elegans.
In 2015, the laboratory of long-time Addgene depositor Alice Ting used yeast display-based directed evolution to create APEX2. They have now applied the same directed evolution technique to the biotin ligase from which BioID was derived, creating a pair of enzymes that overcome both the speed and toxicity limitations of APEX2 and BioID. In the Ting Lab’s recent Nature Biotechnology paper, they describe TurboID and miniTurbo, which utilize non-toxic biotin, but label nearly as quickly as APEX2. What’s more, since the enzymes were ”evolved” in yeast at 30℃, the enzymes function across a much broader temperature range than BioID, which only functions optimally at 37℃. The increased efficiency of TurboID and miniTurbo makes PL a viable method for proteomics in model organisms in which it was previously not an option, including Drosophila and C. elegans.
Find the TurboID plasmids here!
Branon et al. Nat Biotechnol. 2018 PubMed PMID: 30125270.
Changing the way we detect viral outbreaks
Article contributed by Izzy Mueller![]() Listen to the viral detection podcast segment
Listen to the viral detection podcast segment
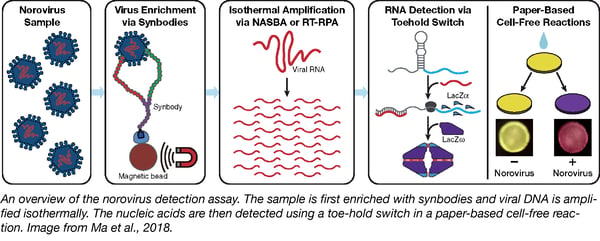
As the primary cause for both the stomach flu and food-borne illnesses, noroviruses can infect millions annually. Because it is highly contagious, it is essential to contain outbreaks when they surface. But detection of the virus costs time and money, and viruses at low concentrations often escape detection. The Alexander Green lab found a solution: a low-cost, cell-free detection assay that can be completed without special equipment. What’s more, detection is based on color changes to the assay paper, so no special equipment or data analyst is necessary.
How does this assay work? The norovirus is enriched with synbodies--or synthetic antibodies--attached to magnetic beads, allowing the virus to be easily concentrated. Viral RNA is then amplified isothermally, and detected through a toehold switch, an RNA sensor that can be used to detect the presence of any specific RNA sequence. In the absence of the target RNA sequence (in this case, norovirus RNA), the ribosome binding site is inaccessible. When the target RNA is present, however, it binds to the switch and exposes its ribosome binding site, allowing for the gene on the toehold switch to be expressed. In this case, the gene encodes the LacZ𝛼 protein. Once expressed, LacZ𝛼 complexes with LacZ𝜔 and forms an active LacZ tetramer. This tetramer cleaves chlorophenol red-b-D-galactopyranoside on the assay paper turning it purple, allowing for easy visual detection of the presence of the norovirus.
While this assay is specific to a particular strain of norovirus, it can be tailored for the detection of other norovirus strains and even other viruses by modifying the sequence of the toehold switch. For example, Green has also developed toehold switches to detect Zika virus (available at Addgene). The plasmids for detecting norovirus will be coming soon!
Ma et al. Synth Bio 2018. Pubmed PMID: 30370338.
SH3 domain collection reveals novel peptide ligand motifs
Article contributed by Michael Lemieux![]() Listen to the SH3 domain podcast segment
Listen to the SH3 domain podcast segment
The human proteome contains a breadth of modular domains that facilitate protein-protein interactions and mediate biochemical processes. One of the largest and best characterized of these is the Src homology 3 (SH3) domain family, known to be involved in cytoskeletal control, cell growth, and endocytosis. Recently, the Sidhu group at the University of Toronto expanded the specificity landscape of the SH3 proteins using peptide-phage display and deep sequencing, revealing that they bind to a much larger subset of protein motifs than previously thought. Sidhu’s group has made several hundred SH3 domain containing plasmids available through Addgene.
These plasmids can be used to carry out any biochemical and biophysical study involving protein stability or binding experiments. Potential experiments that one might perform using the purified domains include protein stability, small molecule binding screens, peptide arrays, and phage display selections.
In addition to these constructs, the Sidhu lab has made hundreds of additional plasmids available through Addgene, for study of the of WW, PDZ, and other protein domains.
 Find the SH3 domain collection here!
Find the SH3 domain collection here!
Teyra et al. Structure 2017. Pubmed PMID: 28890361.

Topics: Other Plasmid Tools, Plasmids





Leave a Comment