Master plasmid fundamentals, CRISPR techniques, AAV serotype selection, and antibody applications. Written by scientists, for scientists.
Subscribe
iGEM isn’t any old science fair. “The world’s biggest synthetic biology competition” brings together hundreds of student teams to build projects and solve problems using molecular biology.
Every few months we highlight some of the new plasmids, antibodies, viral preps, and other materials in the repository through our Hot Plasmids articles. This month, we’ve got some new biosensors for neuroscience research, popular plasmids for a common lab enzyme, and more!
Check us out! This week Addgene rolled out our new brand identity, and we’re feeling sharp. We’re so excited to show you what we’ve been working on.
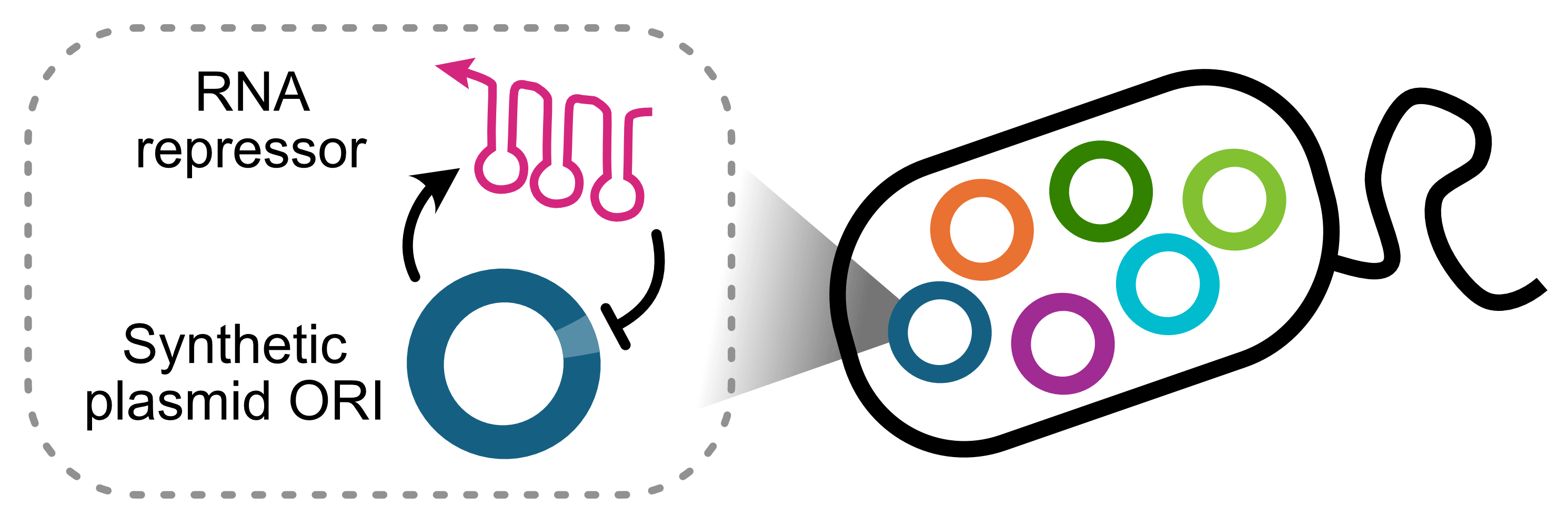
By Baiyang Liu and James Chappell, Rice University. For decades, we’ve been designing experiments around two major limitations of plasmids: copy number and incompatibility. While functional, such workarounds are clunky. To address this, we created a synthetic origin of ...
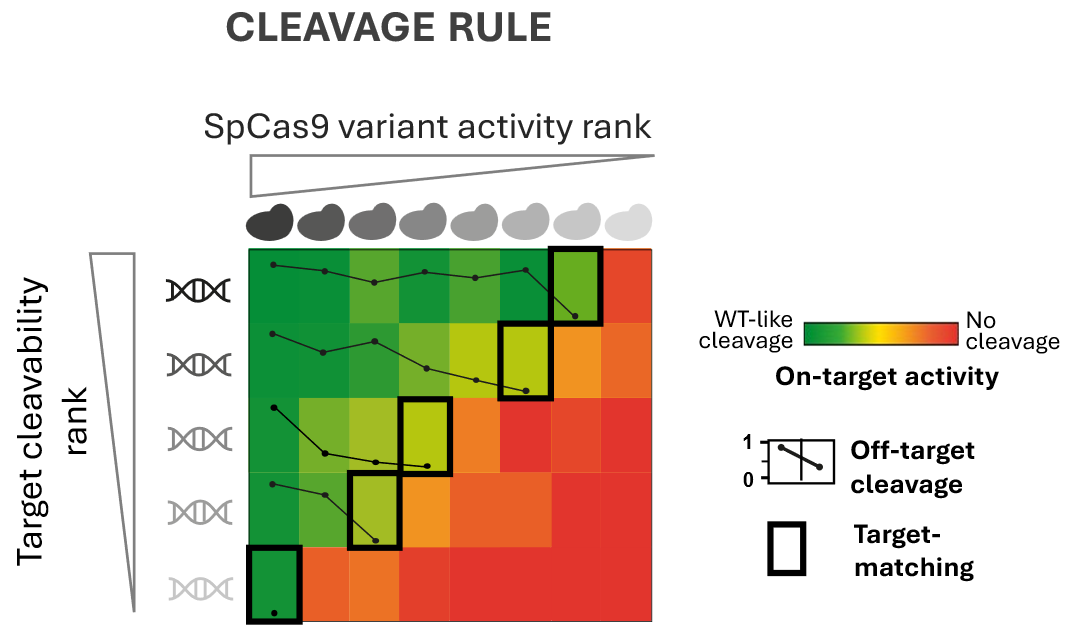
ByBalázs Csoma, Hungarian Research Network CRISPR nucleases are remarkably precise molecular tools for cutting DNA. But “remarkably precise” does not mean “perfectly specific.” In reality, CRISPR nucleases occasionally make mistakes and cleave DNA sequences that only resemble ...
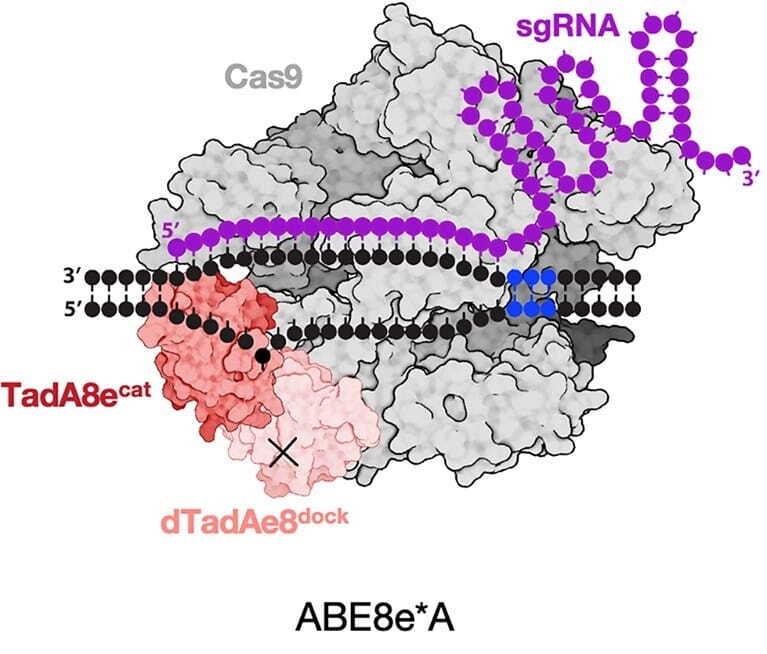
Deaminet 2026, held in Palm Springs in late January, brought together researchers studying deaminase enzymes across disciplines: from structural biologists resolving APOBEC proteins at atomic resolution, to cancer biologists dissecting mutational processes, to medical ...
Do you have a green thumb — or, perhaps, are you one of those people who kills every plant they touch? The whole trouble with houseplants is they can’t bark, meow, or cry when they need something. But what if we could equip plants with a way to warn us about concerning growing ...
Every few months we highlight some of the new plasmids, antibodies, viral preps, and more in the repository through our Hot Plasmids articles. This month, check out hot new AAV packaging plasmids, CRISPR libraries, and more!